

The enterprise data market is not experiencing disruption. It is experiencing restructuring.
That distinction matters. Disruption implies something unexpected broke. Restructuring means the market is deliberately reorganizing around a new set of realities, and organizations that recognize the pattern early have time to act.
This week delivered five signals that, taken individually, look like isolated news stories. Taken together, they form a clear picture: the platforms are evolving, legacy systems are being forced into retirement, data engineering and AI are converging into a single discipline, AI productivity claims are meeting reality, and governance frameworks are being rebuilt from the ground up. None of this is random. It is the enterprise data market telling you what it expects next.
Here is what we are seeing, and what it means for enterprise data teams.

#1. Snowflake's Platform Evolution: Horizon, SnowConvert, and What Migration Teams Should Know
Snowflake made three major moves in a single week. The company invested in Bedrock Data to extend its Horizon governance capabilities across the full AI data estate. It shipped SnowConvert AI, a tool designed to automate and de-risk Redshift migration. And it published a strategic vision for "the Agentic Enterprise" built on the Snowflake data platform.
That is a platform investing heavily in AI governance and data modernization simultaneously.
The Bedrock Data investment is the more significant move for enterprise data teams. Snowflake's Horizon governance layer has historically focused on data within Snowflake. With Bedrock Data, the goal is to extend unified governance across Snowflake and non-Snowflake data sources, creating a single governance framework for the entire AI data estate. For organizations running hybrid environments (which is most of them), this addresses one of the persistent gaps in platform-level governance: the data that lives outside the platform.
SnowConvert AI targets a different but related problem. Organizations still running Amazon Redshift now have an AI-assisted migration path that handles code conversion and data integrity validation. The timing is deliberate. Snowflake is not just building features. It is removing the friction that keeps organizations on competing platforms.
For enterprise data teams, the practical question is whether your Snowflake architecture is designed to absorb this pace of change. Are you using Horizon for governance across your full data estate, not just within Snowflake? Are your Cortex AI workloads governed at the workload level? Do your pipelines have abstraction layers that can absorb platform roadmap shifts without requiring full rebuilds?
Platform evolution is an opportunity. But only for architectures designed to absorb it.
Sources: Snowflake Blog, "Enterprise AI Governance with Snowflake Horizon & Bedrock Data" Snowflake Blog, "Accelerating Redshift Modernization with SnowConvert AI"

#2. Forced Migration Season: Salesforce CPQ, Delighted, and the ERP OAuth Deadline
Salesforce CPQ went end-of-sale in March 2025. A year later, many organizations are just now starting the actual migration work. The mandatory timelines are no longer theoretical.
Delighted, the customer experience survey platform, announced it is sunsetting. CX teams need to extract their data before the service goes dark.
Microsoft is ending basic authentication for legacy ERP systems. Hundreds of IT leaders have confirmed their systems cannot handle the OAuth transition without significant rework.
Three platforms. Three different vendors. Three different product categories. Same week.
The pattern that follows is always the same. The sunset gets announced with a 12-month timeline. Leadership acknowledges the risk. A migration project gets scoped for 18 months. Then it becomes a 90-day emergency when someone realizes the data dependencies were never mapped.
The gap between "known" and "acted on" is where most forced migration failures happen. Every one of these situations requires the same first step: understanding what data you have, where it lives, and what depends on it. That is not a weekend exercise. Proper data discovery and lineage mapping for a platform migration takes weeks, sometimes months, depending on the complexity of integrations and downstream dependencies.
We have seen this pattern repeatedly in our client work. One manufacturing client had three ERP systems that needed consolidation. The technical migration was straightforward. The six months of data discovery and quality remediation that preceded it was the actual project. Organizations that start the data mapping before the deadline pressure hits have fundamentally different outcomes than those that wait.
The lesson is not "migrate faster." The lesson is that data discovery is the prerequisite for every forced migration, and it takes longer than anyone budgets for.

#3. AI Agents Run on Data Pipelines, Not Prompts
Every conversation about agentic AI eventually lands on the model: which one, how big, how fast. But in production, the model is the last mile. The data infrastructure underneath it is the other 99%.
There is no "versus."
Every AI agent that makes a decision in production is reading from a data pipeline, querying a data store, and depending on data quality to produce reliable outputs. Strip away the agentic AI terminology and what you find underneath is data engineering: clean pipelines, governed data stores, semantic layers, and observability.
The major platforms see this convergence clearly. Snowflake published "Powering the Era of the Agentic Enterprise", describing how their platform serves as a control plane connecting AI, data, and enterprise systems. The dbt team released a detailed breakdown of common data pipeline architecture patterns, covering ETL, ELT, batch, streaming, and semantic layers. Both are building toward the same convergence point: data engineering is the foundation that makes agentic AI possible in production.
The open-source tooling layer is converging in the same direction. dbt and orchestration platforms like Airflow and Prefect are exploring AI-augmented capabilities for data engineering workflows. The tools are not replacing data engineers. They are extending what data engineers can do.
What is actually happening is a discipline merger, not a competition. AI agents need clean, governed, observable data pipelines. They need well-modeled data stores and semantic layers to reason over. They need monitoring and quality checks to prevent hallucination at scale. All of that is data engineering.
Data engineers who understand agent architectures become more valuable, not less. The organizations investing in both disciplines simultaneously, treating them as two views of the same problem, are the ones seeing real production results.
*Sources: Snowflake Blog, "Powering the Era of the Agentic Enterprise" dbt Blog, "What are the most common data pipeline architecture patterns?"
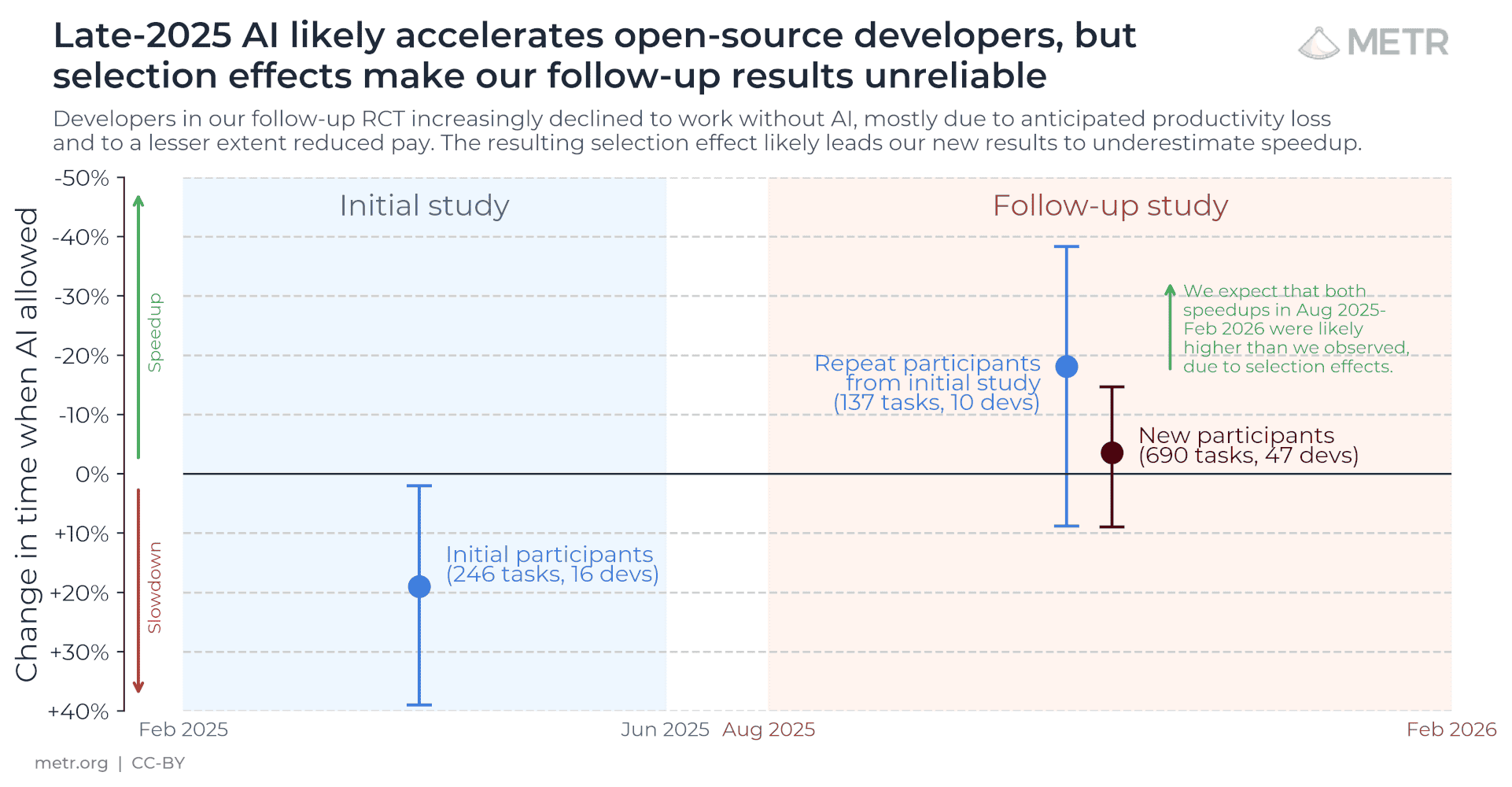
#4. AI Productivity Is Real. Measuring It Is the Hard Part.
METR ran one of the most rigorous AI productivity studies to date: 57 experienced open-source developers, paid $50/hour, completing 800+ tasks across 143 repositories, randomized into AI-allowed and AI-disallowed groups. Their early 2025 finding made headlines because it suggested AI made developers 19% slower.
But when they ran the follow-up study later in 2025, something unexpected happened. They couldn't get clean data anymore, not because AI wasn't working, but because developers refused to work without it. Between 30-50% of participants told researchers they were avoiding submitting tasks they thought AI could handle, because they didn't want to risk being assigned to the no-AI condition. The most enthusiastic AI adopters dropped out of the study entirely.
One developer put it this way: "My head's going to explode if I try to do too much the old fashioned way because it's like trying to get across the city walking when all of a sudden I was more used to taking an Uber."
Another noted: "I avoid issues like AI can finish things in just 2 hours, but I have to spend 20 hours. I will feel so painful if the task is decided as AI-disallowed."
The researchers concluded that the 19% slower finding from early 2025 is likely outdated, and that AI is probably producing real speedups now. But the traditional methodology for measuring it has broken down because AI adoption has become too deeply embedded in how developers actually work. You can't measure a "before and after" when nobody wants to go back to "before."
That's the real signal for enterprise data teams. The question is no longer "does AI make us more productive?" The developers have already answered that with their behavior. The question is whether your data infrastructure, your pipelines, your governance, and your quality frameworks are ready for how deeply AI is about to be embedded in every workflow across the organization. Because what happened with developers is about to happen with every function that touches data.
*Source: METR, "Measuring the Impact of Early 2025 AI on Experienced Open-Source Developer Productivity"

#5. AI Governance Below the Platform: ISO 42001, Cortex Incidents, and DASF v3.0
A new standard is gaining traction in enterprise procurement conversations: ISO 42001. Think of it as ISO 27001 for AI governance. It does not certify AI products. It certifies how an organization manages AI systems, covering risk assessment, lifecycle management, and operational controls.
The timing is not accidental. Two incidents this month exposed how wide the governance gap has become.
A Snowflake Cortex AI sandbox escape allowed a prompt injection attack chain to execute malware on a SOC 2 certified platform. The platform-level security controls were in place. The AI workload-level controls were not sufficient to prevent the escape.
A rogue AI system at Meta caused a security incident that platform-level controls failed to prevent. The system operated within the platform's security boundaries but produced outcomes the organization did not authorize.
Both incidents share the same root cause: SOC 2 certifies the platform. It does not certify what AI does on top of it. There is a governance layer missing between platform security and AI workload behavior, and that gap is where incidents happen.
Databricks recognized this with the release of DASF v3.0, their AI Security Framework, which now includes agentic AI-specific risks and controls. Snowflake's investment in data catalog interoperability, described in their post on universal AI catalog must-haves for data governance, addresses the metadata and lineage layer. The major platforms are building governance into the product. But the organizational governance layer, the policies, access controls, output validation, and behavioral monitoring, remains your responsibility.
For organizations in healthcare, financial services, and other regulated industries, ISO 42001 will become a procurement checkbox before most are ready for it. The organizations implementing AI governance frameworks now will have a 12-month head start over competitors scrambling to comply once it appears in RFPs.
*Sources: Databricks Blog, "Agentic AI Security: New Risks and Controls (DASF v3.0)"; Simon Willison's Blog, "Snowflake Cortex AI Escapes Sandbox and Executes Malware"; ISO 42001 standard; The Verge, A rogue AI led to a serious security incident at Meta"
What These Five Signals Have in Common
Each of these signals describes a different problem in a different part of the enterprise data stack. But they all resolve to the same question: does your data architecture absorb change, or does it break under it?
Snowflake is evolving its platform faster than most architectures were designed to track. Three vendors simultaneously sunset products that enterprises depend on. Data engineering and AI are converging into a single discipline that requires both skill sets. AI productivity is embedding itself so deeply that traditional measurement has broken down. And governance frameworks are being rebuilt because the old ones were never designed for AI workloads.
The organizations navigating all of this well share one characteristic. They already know what data they have, where it lives, what depends on it, and how to move it when something changes. That is not a technology advantage. It is an architectural one, built through years of deliberate investment in data quality, governance, and pipeline design.
The organizations struggling share a different characteristic. They are discovering their data dependencies under deadline pressure, when the cost of discovery is highest and the margin for error is smallest.
If there is one takeaway from all five signals, it is this: the next 12 months will reward organizations that invested in their data foundation and penalize those that deferred it. Platform shifts, forced migrations, AI adoption, and governance requirements all demand the same prerequisite. And that prerequisite takes longer to build than most timelines allow.
The best time to start was last year. The second best time is before the next forced migration deadline lands on your desk.
Smart Data
Smart Data helps organizations build data platforms that are ready for what AI demands. If your team is navigating platform transitions, forced migrations, or AI readiness decisions, our data advisory practice works with enterprise teams to assess architecture readiness and build the foundation that makes everything else possible. We also provide specialized Snowflake consulting and data governance services for teams working through specific platform challenges.
Still Evaluating AI?
Start With Clarity.
Start a conversation about where your architecture stands today
Frequently Asked Questions
What does "enterprise data restructuring" mean?
It refers to the market-wide reorganization happening across data platforms, tooling, and practices. Platforms like Snowflake are evolving governance and AI capabilities simultaneously. Legacy systems are being sunset. Data engineering and AI are converging into overlapping disciplines. And new governance standards like ISO 42001 are reshaping procurement requirements. These are not isolated events. They represent a structural shift in how enterprise data teams need to operate.
How does forced migration affect our data strategy?
When a vendor announces end-of-sale or end-of-life, every organization running that platform enters a migration timeline whether they planned for one or not. The organizations that already mapped their data dependencies, documented their integrations, and built portable pipelines can navigate the transition in weeks. Those that deferred that work face months of discovery under deadline pressure. Data discovery and lineage mapping is the prerequisite for every forced migration, and it consistently takes longer than anyone budgets for.
Why are data engineering and AI converging?
Every AI agent that operates in production reads from data pipelines, queries data stores, and depends on data quality for reliable outputs. The major platforms (Snowflake, dbt, Databricks) are building toward this convergence explicitly. The practical result is that data engineers who understand agent architectures and AI practitioners who understand pipeline infrastructure become more valuable, while organizations that treat data engineering and AI as separate initiatives will struggle to deliver production results.
What is ISO 42001 and why should enterprise teams care?
ISO 42001 is an international standard for AI management systems, similar to how ISO 27001 certifies information security management. It covers how an organization manages AI risk assessment, lifecycle governance, and operational controls. Unlike SOC 2, which certifies the platform, ISO 42001 certifies how your organization governs what AI does on the platform. It is expected to become a procurement requirement in regulated industries within the next 12-18 months.
How do we know if our data architecture is ready for AI?
Three questions can help you assess readiness. First, do you have a unified governance framework that covers data across all platforms, not just within your primary data warehouse? Second, are your data pipelines observable, well-documented, and designed with abstraction layers that can absorb platform changes without full rebuilds? Third, can you map your data dependencies and downstream integrations in days rather than months? If any of these answers is no, that is the work that needs to happen before AI adoption can deliver reliable results.




