The Problem
The 56% Problem
PwC's 29th Global CEO Survey asked 4,454 CEOs across 95 countries about AI returns. The finding that should reshape every AI conversation at the leadership level: 56% report neither revenue nor cost benefits from their AI investments.
Not disappointing returns. Not "below expectations." Neither revenue nor cost benefits. Two years running.

Meanwhile, Deloitte's State of AI in the Enterprise found that only 25% of organizations have moved 40% or more of their AI experiments into production. Three out of four enterprises are stuck in pilot mode, running experiments that never become operational systems.
Capgemini's Top Tech Trends of 2026 frames the shift directly: "Technology leadership in 2026 is no longer about experimentation but about constructing durable foundations." The models are not the problem. GPT-5.4, Claude, Gemini, Snowflake Cortex AI, and Microsoft Foundry are genuinely capable systems. The technology works. What does not work is deploying it on top of data that is not ready to support it.
This guide breaks down why AI initiatives fail, what data-ready companies do differently, and how to evaluate whether your organization is positioned to generate real returns from ai implementation services and AI enablement investments.
Key Takeaways
56% of CEOs report zero AI returns (PwC, 4,454 CEOs across 109 countries). The gap is not the technology. It is the data foundation underneath.
92% of early adopters on governed data report positive ROI (Snowflake, 2,050 organizations). Data-ready companies invest in integration, governance, and quality before AI.
Only 25% of organizations have moved 40% or more of AI experiments into production (Deloitte). Three out of four are stuck in pilot mode.
A practical assessment of your data environment takes 2-3 weeks and can prevent 6-12 months of misdirected AI investment.
The Pattern
What Data-Ready Companies Actually Do Differently
The companies generating real returns from AI are not using better models. They are not spending more. They are doing something much less exciting but far more effective: investing in the data foundation for AI before they invest in the AI itself.
This does not mean waiting years to "get the data perfect." Perfection is not the goal. Readiness is.
Here is what readiness looks like in practice.

They Assess Before They Build
Before selecting an AI use case, data-ready companies assess their actual data environment. Where does the data live? What is the quality? What is documented and what is tribal knowledge? Where are the gaps between what exists and what the intended AI use case requires?
This is the step most enterprises skip. The assumption is "we have data, so we can do AI." But having data and having data that can support a specific AI use case are fundamentally different things.
The Anthropic State of AI Agents Report surveyed 500+ technical leaders and found that 42% cite data quality requirements as the top barrier to scaling AI agents. Not model capability, not compute costs, not talent shortages. Data quality. An AI readiness assessment takes two to three weeks. Skipping it can cost six to twelve months of wasted effort when the pilot stalls on data problems that could have been identified upfront.


The payoff for treating governance seriously is substantial. According to Databricks' State of AI Agents report, companies using AI governance put over 12x more AI projects into production than those without it. That is not a marginal improvement. It is an order-of-magnitude difference. The same report found that AI governance investment grew 7x in nine months, suggesting that enterprises are beginning to recognize what the data shows: governance is not overhead. It is a production accelerator.
Without governance, even a well-built AI system degrades over time. New data sources get connected without documentation. Definitions drift as teams make local changes. The model outputs slowly become unreliable, and nobody can pinpoint when or why the degradation started. And the risk is not just accuracy. Flexera's 2026 State of the Cloud Report found that 53% of organizations rank security and compliance as their number one cloud concern, ahead of cost and performance. Governance is not just a data quality issue. It is a security issue.

Self-Assessment
Data Maturity Self-Assessment
Be honest with these five questions. The gap between what you assume and what you discover is usually where the AI budget goes to die.
Self-Assessment
1Can you inventory every system where customer data lives?
2When was your last data pipeline audit?
3Do all departments use the same definitions for key metrics?
4Can you trace any dashboard number back to its source system?
5Do you have documented data ownership for each domain?
This is a simplified version of the assessment we run in the 360 AI Workshop. The full workshop includes a complete data source inventory, pipeline reliability analysis, governance maturity scoring across five dimensions, use case prioritization with ROI estimates, and a recommended architecture tied to your specific systems and objectives.
Want the full diagnostic? The 360 AI Workshop runs a comprehensive version of this assessment across your entire data landscape in 2-3 weeks. Schedule a workshop
In Practice
Industry Perspectives: How AI Enablement Applies in Practice
AI enablement is not a generic exercise. The data challenges, regulatory constraints, and high-value use cases vary significantly by industry. Here is how the pattern plays out in three sectors where enterprise data complexity is highest.
Healthcare
The data challenge in healthcare is not volume. It is fragmentation and compliance. Clinical data in one system, billing in another, administrative records in a third, all governed by HIPAA and interoperability standards like HL7 and FHIR. Most healthcare organizations have invested in each of these systems independently, which means the data exists but cannot be joined without significant integration work.
A healthcare payer organization discovered $16M in recoverable Medicaid revenue during a data quality assessment. The revenue was not lost due to billing errors. It was invisible because the data systems that tracked eligibility, claims, and payments were not connected in a way that surfaced the gap. The value was in the data assessment itself, not in any model or algorithm. Connecting and cleaning the data was where the real work happened, and it is exactly the kind of foundation work that makes AI use cases viable afterward.

In another case, a healthcare technology firm engaged a 13-person managed data team to maintain and modernize its data infrastructure, with the engagement running through 2027. That kind of sustained investment reflects the reality that healthcare data is not something you fix once. It requires ongoing governance as regulations change, systems evolve, and data volumes grow.
Where AI delivers value in healthcare: Claims processing automation, patient risk scoring, clinical documentation, and compliance monitoring. Each of these depends on data that is clean, connected, and governed. As the Deloitte survey confirmed, the vast majority of enterprises have not moved their AI experiments to production, and healthcare is no exception. The prerequisite is always the same: the data foundation has to support it.
Manufacturing
Manufacturing data is uniquely challenging because it spans operational technology (sensor feeds, MES systems, IoT devices) and enterprise systems (ERP, supply chain, quality management). The data formats, frequencies, and reliability levels differ dramatically between these two worlds.
A national distributor operating on three separate ERP systems consolidated to a single platform (NetSuite), using GenAI-assisted data migration to interpret and map fields across incompatible schemas. The migration itself was the enablement step. Once the data lived in a single governed platform, AI use cases like inventory optimization and demand forecasting became viable.
At another manufacturer, an SAP S/4HANA portal integration connected customer-facing data with back-office systems, eliminating the manual handoffs that introduced errors and delays. These kinds of integration projects do not get press coverage, but they are the infrastructure that makes production AI possible.
Where AI delivers value in manufacturing: Predictive maintenance, supply chain optimization, quality control automation, and demand forecasting. Snowflake's Data + AI Predictions 2026 report notes that manufacturing AI adoption is taking center stage in 2026, driven by the convergence of operational data and enterprise analytics on modern data platforms.
Distribution and Supply Chain
Distribution companies operate on razor-thin margins where data visibility across warehouses, suppliers, and logistics networks directly determines profitability. When operational data lives in one ERP, inventory in another, and customer orders in a third, the integration layer becomes the business-critical infrastructure that everything else depends on.
A national distributor with 660+ locations needed a unified data platform for reporting across a complex multi-site operation. The team recruited, vetted, and managed 100+ offshore engineers integrated with the client's existing IT organization, building the data infrastructure that connected fragmented operational systems into a single reporting layer. A separate manufacturing client consolidated three separate ERPs into NetSuite, using GenAI-assisted data migration to handle the complexity of mapping decades of operational data across incompatible systems.
Where AI delivers value in distribution and supply chain: Demand forecasting, inventory optimization, logistics routing, supplier risk scoring, and automated reorder systems. These use cases require clean, connected operational data across multiple locations and systems. The data platform work comes first.
Our Approach
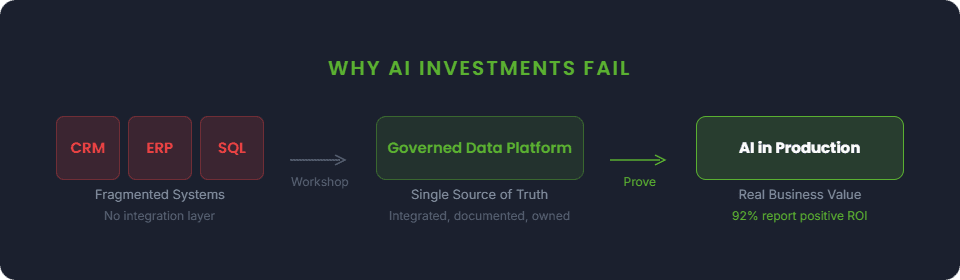
Workshop. Prove. Scale.
Buyers evaluating ai development services need honest numbers, not "it depends" followed by a request to schedule a call. Our approach follows three phases, each with a clear scope, timeline, and deliverable. You decide whether to proceed at each step.

Workshop
2-3 weeks | $15,000-$25,000
The workshop is a structured assessment of your data landscape, current capabilities, and AI readiness. It produces a maturity scorecard, a prioritized roadmap of use cases ranked by business impact and data readiness, a recommended architecture, and a Phase 2 SOW estimate.
Phase 1
Prove
4-10 weeks | $40,000-$70,000
The Prove phase builds a proof of value on real production data. Not a demo. Not a prototype running on sample data. A working system connected to actual data that produces a measurable business outcome.
Phase 2
Scale
Ongoing | Variable
Production deployment with monitoring, governance, retraining schedules, and ongoing team support. Managed services, staff augmentation, or hybrid delivery based on your team's needs.
Phase 3
Not sure where your organization stands?
Our 360 AI Workshop maps your data landscape and identifies realistic AI use cases in 2-3 weeks
For context, Fivetran's 2026 Enterprise Data Infrastructure Benchmark found that enterprises spend an average of $29.3M annually on data programs. A $15,000-$25,000 workshop represents less than 0.1% of that spend and is designed to ensure the other 99.9% is directed effectively.
The three-phase structure exists because the most expensive mistake in enterprise AI is scaling a system that was never validated against real data. Each phase produces a decision point. You can stop, adjust, or proceed based on evidence rather than assumptions.
Among organizations that invested in data foundations before deploying AI, the Snowflake ROI data showed an average quantified return of 49%. The Scale phase is where that return materializes, but only if the Workshop and Prove phases confirmed the foundation can support it.
The pattern holds whether you are evaluating ai implementation services for the first time or recovering from a previous initiative that stalled. The sequence matters more than the speed.
The Evidence
What 2026 Research Shows
The PwC CEO Survey finding is not an outlier. We broke down the full pattern in Why Most Enterprise AI Investments Fail. But the failure stat is not the whole picture. Here is what happens when you look across the full body of 2026 research:

The early adopter story is very different. Snowflake's ROI of Gen AI and Agents report, surveying 2,050 organizations worldwide, found that among those who quantified returns, the average is 49%, a 20% increase over the prior year. Only 5% of C-level leaders at these organizations say returns have been flat. Effectively zero report negative returns.
Agent deployments are already delivering. Anthropic's State of AI Agents report found that 80% report measurable economic returns. Not projected value or pilot results, but actual ROI from deployed systems.
Process and tooling multiply results. Databricks found that companies using evaluation tools get nearly 6x more AI projects into production. Those using AI governance: the 12x multiplier noted earlier. The difference is not talent or budget. It is rigor.
The industry consensus is converging. Capgemini's Top Tech Trends of 2026 puts it directly: "The era of experimental AI is giving way to the need for solid AI foundations: reliable data, clear governance, scalable architectures." Gartner's 2025 Hype Cycle for AI confirms the direction, identifying AI-ready data as one of the two fastest-advancing technologies on the cycle.
So how do you reconcile PwC's 56% with Snowflake's 92%?
The answer is in the survey populations. PwC surveys all CEOs, across every industry, every maturity level, every budget tier. That includes organizations that purchased AI tools without investing in data infrastructure, organizations running a single chatbot and calling it an AI initiative, and organizations that have not yet moved a single experiment to production. Snowflake surveys early adopters who invested in data platforms and foundations before deploying AI on top of them.
Both studies are accurate. The gap between them IS the data foundation for AI. Companies that built the foundation before adding AI see returns. Companies that skipped ahead do not. The sequence of investment determines the outcome.







