

What Stanford's 2026 AI Index Means for Enterprise Data Teams
Stanford's Human-Centered AI Institute published the 2026 AI Index Report in April. At over 400 pages, it is the most comprehensive independent assessment of where AI stands as a technology, an industry, and an enterprise reality.
We read the entire report. Most of the coverage focuses on model benchmarks and investment totals. Those numbers matter, but they are not what enterprise data leaders need to act on. What matters is the gap the report documents between organizations that adopted AI and organizations that can actually operate it at scale.
Here is what the data says, organized around the decisions enterprise data teams are making right now.
The Adoption-Scaling Gap Is a Data Foundation Problem
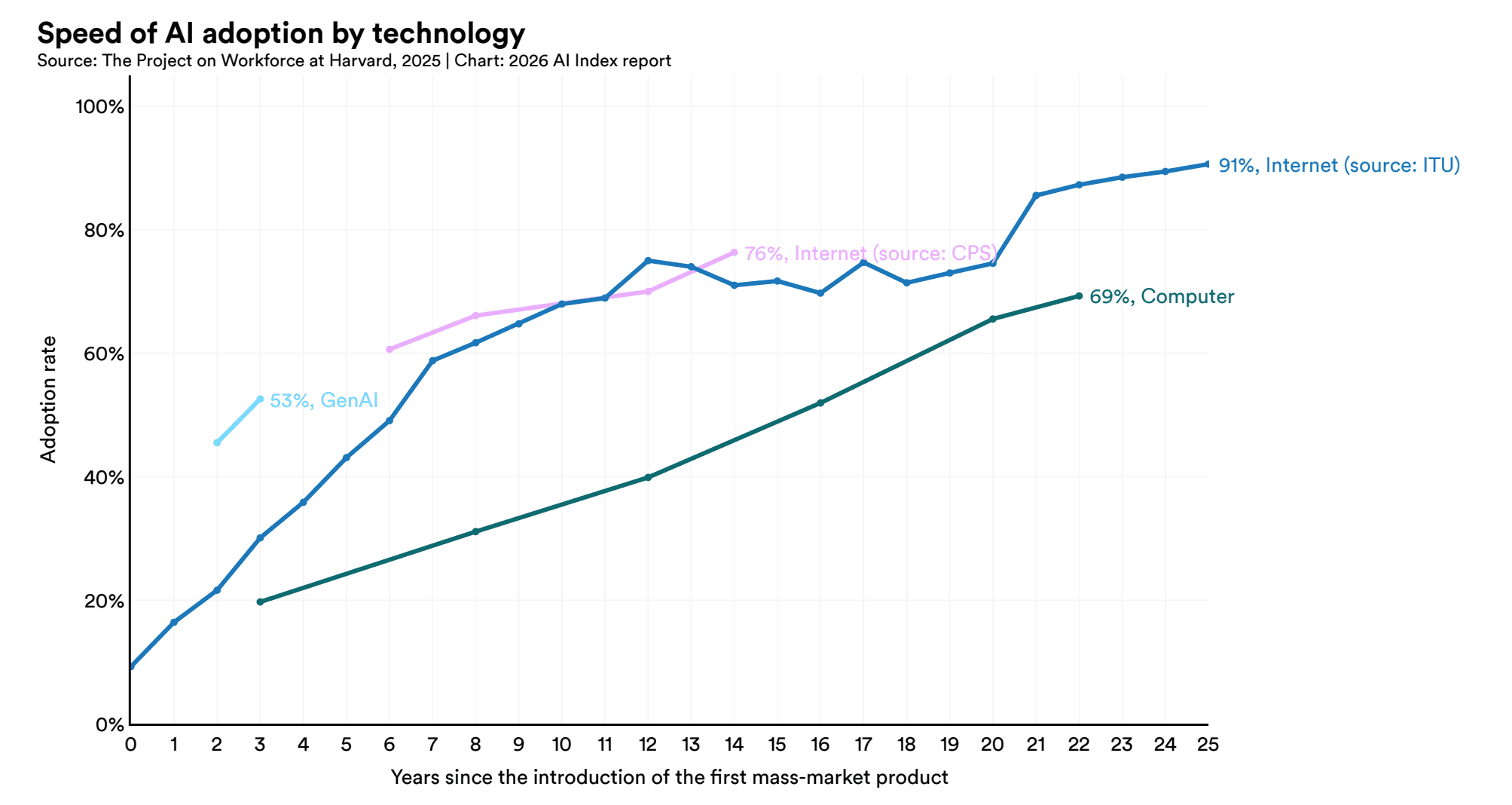
Source: Stanford HAI 2026 AI Index Report. hai.stanford.edu/ai-index/2026-ai-index-report
The Stanford AI Index 2026 reports that 88% of organizations now use AI in at least one business function. That number has been climbing steadily for years and is no longer surprising.
The number that should concern every CTO and VP of Engineering is the one right next to it: fewer than 10% of organizations have fully scaled AI in any single business function.
That is not a rounding error. It means roughly 80% of enterprises have adopted AI tools without deploying them at production scale. They have pilots. They have proofs of concept. They have licenses and vendor contracts. What they do not have is AI operating reliably inside a business process, producing trusted outputs, governed and monitored.
This adoption-scaling gap is not a technology problem. The models are capable. SWE-bench coding performance, one of the report's technical benchmarks, went from 60% to near 100% of human baseline in a single year. The models are getting better faster than most enterprises can absorb them.
The bottleneck is underneath the model. It is the data layer: fragmented sources, ungoverned pipelines, conflicting definitions across systems, and missing lineage. When the data feeding an AI system is unreliable, the system cannot scale regardless of how capable the model is.
Global AI private investment reached $110.4 billion in 2025, up 39% year over year. Data management and processing investment alone hit $31.58 billion. The market is telling the same story the adoption numbers tell: the infrastructure layer is where the real work is.
If your organization is part of the 88% that has adopted AI but not the sub-10% that has scaled it, the path forward is not more tools. It is the foundation work that makes those tools reliable in production. We wrote about this pattern in detail in Why Most Enterprise AI Investments Fail.
Quality and Governance Are Now Non-Optional
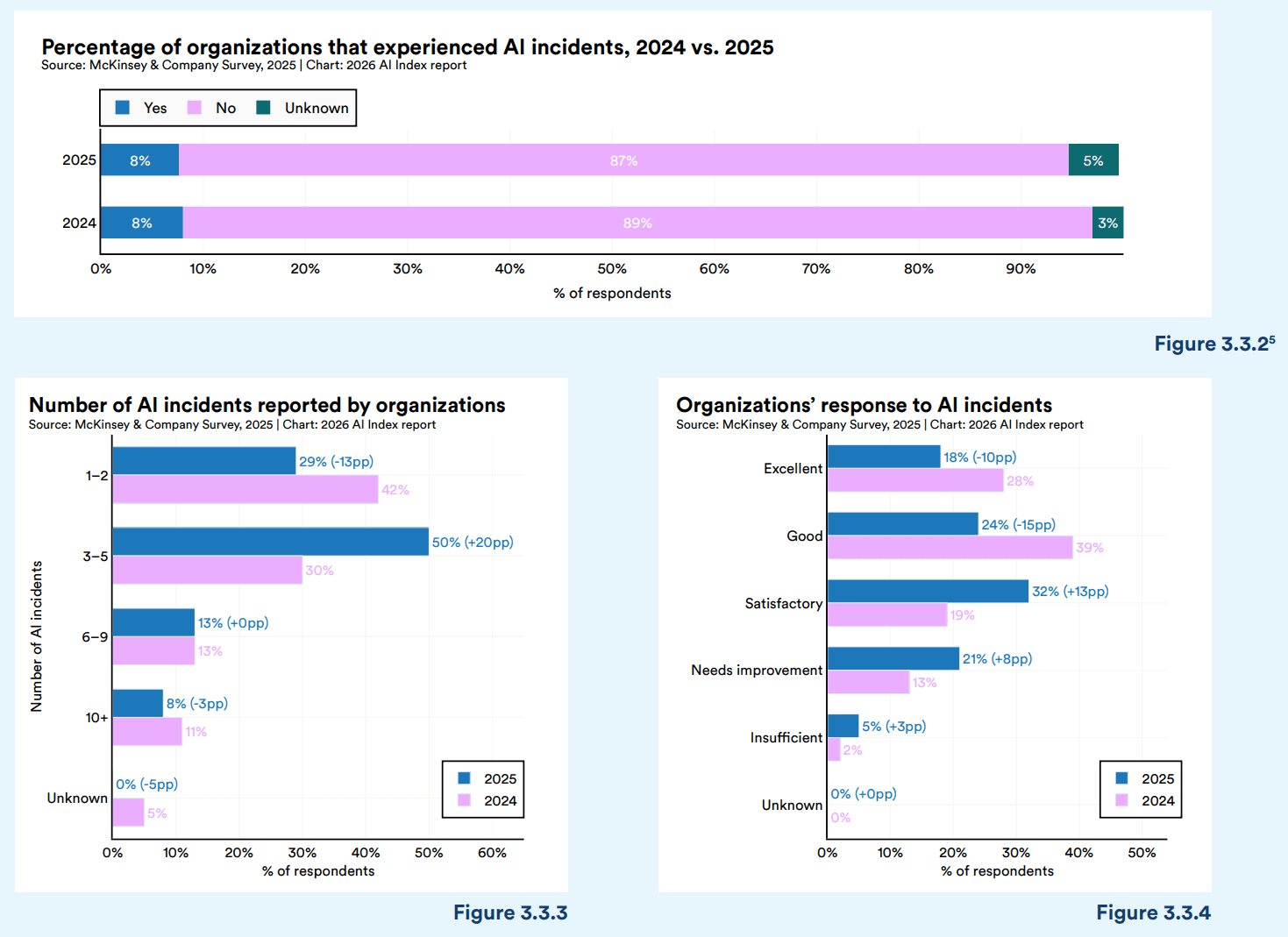
Source: Stanford HAI 2026 AI Index Report. hai.stanford.edu/ai-index/2026-ai-index-report
The Stanford report draws on McKinsey's annual survey tracking how organizations perceive AI risk. The 2026 findings are unambiguous.
74% of respondents now cite inaccuracy as their top AI risk. That is up 14 percentage points in a single year, making data quality the number-one concern ahead of cybersecurity (72%), regulatory compliance (63%), and privacy (54%).
The concern is grounded in measurable reality. When Stanford assessed hallucination rates across 26 leading foundation models, the range spanned from 22% to 94%. Even the best-performing models produce inaccurate outputs roughly one in five times. For an enterprise running AI in a production workflow, processing claims, generating financial reports, making operational recommendations, a 22% hallucination rate is a serious operational risk.
AI incidents increased 55% year over year, reaching 362 documented cases. These are not theoretical risks. They are real failures in production systems affecting real organizations.
At the same time, the transparency that enterprises depend on from model providers is declining. The Foundation Model Transparency Index, which measures how much frontier AI companies disclose about their training data, compute resources, and deployment practices, dropped from 58 to 40 out of 100. Model vendors are disclosing less about how their systems work even as enterprises are deploying those systems into sensitive business processes.
The implication is straightforward. Enterprises cannot outsource AI quality to the model provider. Your data governance framework, your validation protocols, your monitoring infrastructure, these are what stand between your organization and the 74% inaccuracy risk the report documents.
Organizations that invested in governance are seeing returns. AI-specific governance roles grew 17% in 2025. The share of businesses with no responsible AI policies dropped from 24% to 11%. Organizations that committed serious resources to responsible AI practices report measurable impact on their bottom line.
The organizations treating governance as overhead are the same ones reporting the highest inaccuracy risk. The organizations treating it as infrastructure are the ones scaling AI into production.
The Talent Shift Enterprise Leaders Need to Plan For
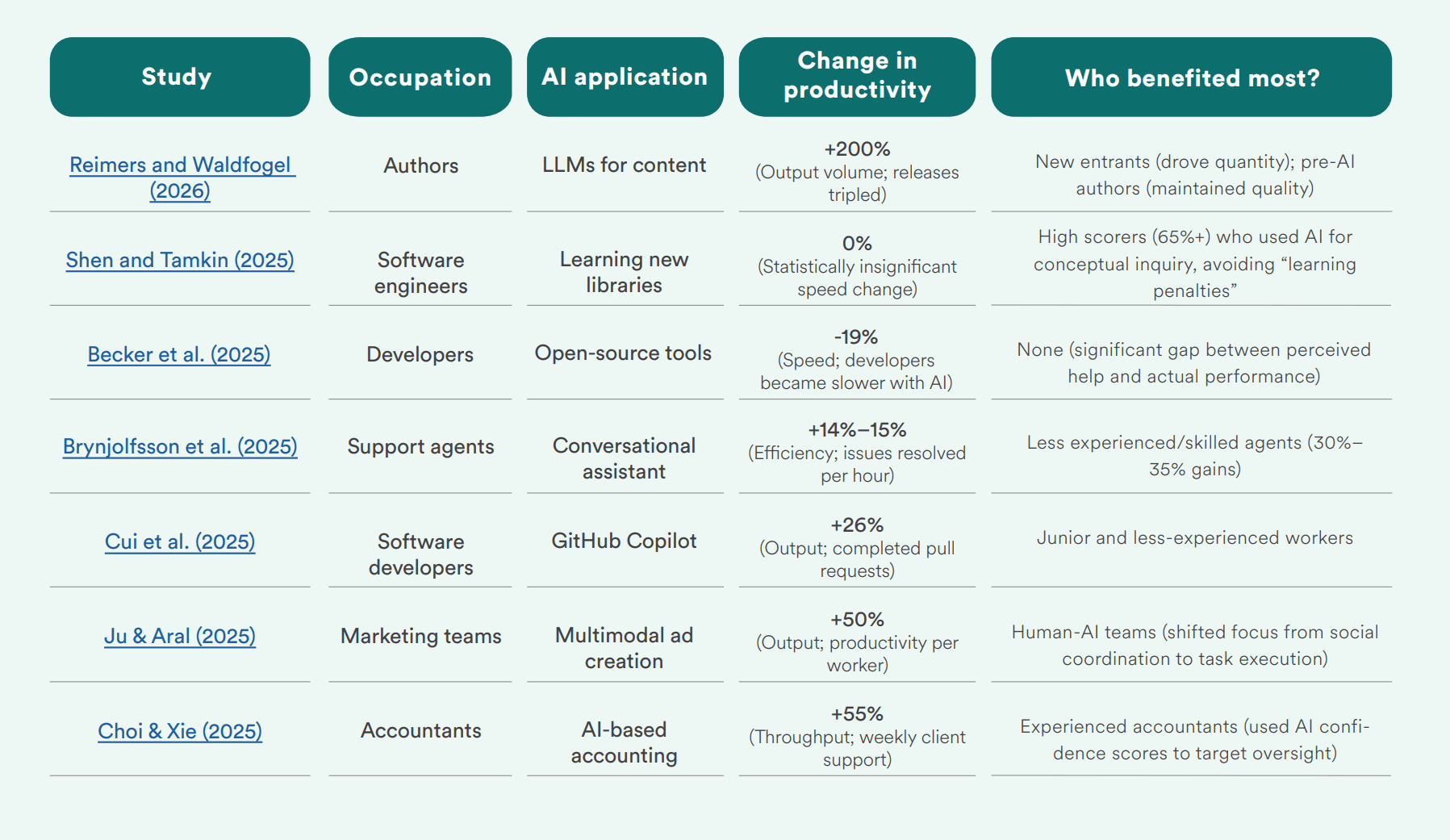
Source: Stanford HAI 2026 AI Index Report. hai.stanford.edu/ai-index/2026-ai-index-report
The Stanford report documents a workforce shift that goes beyond the usual "AI will take jobs" narrative. The data is more specific and more actionable than the headlines suggest.
Employment for software developers ages 22 to 25 fell nearly 20% from its 2024 peak. Entry-level developer hiring is contracting in a measurable, sustained way. At the same time, demand for experienced workers continues to grow.
This is happening alongside a dramatic surge in AI-specific hiring. Agentic AI job postings grew 10,854% year over year. AI governance roles grew 17%. The labor market is not shrinking. It is restructuring around AI, and the restructuring is hitting entry-level positions hardest.
There is also a significant perception gap. 73% of AI experts expect AI to have a positive impact on jobs over the next 30 years. Only 23% of the general public agrees. That 50-point gap matters for enterprise leaders managing organizational change. Your technical leadership may be enthusiastic about AI's potential while the broader workforce is uncertain or resistant. Ignoring that gap creates adoption friction from within.
For enterprise data teams, the talent implications are practical.
First, the junior pipeline that historically trained the next generation of data engineers, analysts, and platform specialists is narrowing. If AI handles the tasks that entry-level engineers used to learn on, the development path for mid-level and senior talent changes. Organizations that do not plan for this will face a skills gap in three to five years.
Second, the demand for governance, quality, and oversight roles is growing. The same report that shows entry-level coding roles declining shows governance and AI operations roles expanding. The talent your data team needs in 2027 looks different from the talent it needed in 2024.
Third, productivity gains from AI are real but uneven. Stanford compiled multiple studies showing 14-26% productivity improvements in structured work tasks, customer support, code completion, financial analysis. But for tasks requiring deeper reasoning and domain expertise, the results are mixed. Open-source developers using AI assistance actually became 19% slower. The gains depend on the task, the integration, and the data.
What Data-Ready Organizations Do Differently
Across every section of the Stanford report, a consistent pattern separates organizations that are scaling AI from those stuck in pilot mode. The differentiator is not the model. It is what sits underneath it.
They invested in the data layer before the AI layer. The $31.58 billion in data management and processing investment is not coincidental. Organizations scaling AI invested in governed data platforms, reliable pipelines, and quality frameworks before deploying models on top of them. The organizations that started with the model and assumed the data would follow are the ones represented in the adoption-scaling gap.
They built governance into the architecture, not around it. The report shows that organizations with formal AI governance structures are scaling more projects into production and reporting fewer incidents. Governance is not a compliance exercise that runs parallel to engineering. It is an engineering requirement: data quality checks, lineage tracking, access controls, monitoring, and validation built into the platform from the start.
They are rethinking their talent strategy. With entry-level roles contracting and governance roles expanding, data-ready organizations are adjusting how they hire, train, and structure their teams. They are investing in AI literacy across the organization while building specialized governance and operations capabilities within the data team.
They treat AI accuracy as a data problem, not a model problem. When 74% of organizations cite inaccuracy as their top AI risk, the instinct is to look for a better model. Data-ready organizations look at the data feeding the model instead. They invest in validation frameworks, human-in-the-loop review processes, and monitoring systems that catch quality issues before they reach production.
They plan for production from day one. A proof of concept that works on sample data proves nothing about production viability. Data-ready organizations build their proofs of value on actual production data, plan for monitoring and maintenance, and staff for ongoing operations. The sub-10% that have scaled AI did not get there through better demos. They got there through production-grade data platforms and disciplined deployment practices.
Smart Data's Perspective
We are a data foundation specialist. We have spent 20 years building data platforms and enterprise software for organizations in healthcare, manufacturing, financial services, and distribution. The Stanford report confirms what we see in every enterprise engagement.
The organizations asking us for AI help rarely have a model problem. They have a data problem. Fragmented sources, ungoverned pipelines, missing lineage, conflicting definitions. The AI layer cannot compensate for a weak data layer, no matter how capable the model is.
Our approach starts where the Stanford data says the gap is: the foundation. Before selecting an AI vendor or committing to a use case, we help organizations assess their data landscape, identify governance gaps, and build the platform infrastructure that makes AI reliable in production.
That is not a technology sale. It is an advisory engagement that maps your current state to your AI ambitions and builds a concrete plan to close the gap.
If you are part of the 88% that has adopted AI but have not yet scaled it, the Stanford report is telling you why. The answer is not more tools. It is the infrastructure underneath them.
Not sure if your data is ready for AI?
Start with our AI Enablement Guide to assess where your organization stands before committing to an implementation.
Frequently Asked Questions
What percentage of companies are using AI in 2026? According to the Stanford AI Index 2026, 88% of organizations now use AI in at least one business function. However, fewer than 10% have fully scaled AI in any single business function, indicating a significant gap between adoption and production deployment.
Why are enterprise AI projects failing to scale? The primary barrier is not the AI model itself but the data infrastructure supporting it. Organizations that lack governed data pipelines, reliable integration layers, and quality frameworks cannot move AI from pilot to production. Stanford's data shows that 74% of organizations cite inaccuracy as their top AI risk, which is fundamentally a data quality and governance problem.
How is AI affecting the job market in 2026? Entry-level software developer employment fell nearly 20% from its 2024 peak, while AI governance roles grew 17% and agentic AI job postings surged 10,854%. The labor market is restructuring around AI rather than shrinking overall, with the biggest impact on junior roles and the biggest growth in governance, operations, and experienced engineering positions.
What should enterprise data teams do based on the Stanford AI Index? Focus on the data foundation before scaling AI. That means assessing data quality, building governance frameworks, investing in reliable pipelines and platform infrastructure, and rethinking talent strategy to account for the shift toward governance and AI operations roles. The organizations scaling AI successfully started with infrastructure, not applications.
The Stanford HAI 2026 AI Index Report is available at hai.stanford.edu/ai-index/2026-ai-index-report. All statistics cited in this post are sourced from the report.
Smart Data has spent two decades building data platforms and enterprise software for organizations in healthcare, manufacturing, financial services, and distribution. Clients include Fortune 500 healthcare payers, national distributors, and mid-market manufacturers across the US.
If you want to know whether your data is ready to support AI at scale, start with the assessment that maps your current state to your ambitions.


