

AI Has Outrun the Infrastructure Underneath It. Here Are 5 Signals From April 2026.
The enterprise AI conversation changed tone in April 2026.
For the last two years, the story was adoption. Who was using it, who was experimenting, who was falling behind. The numbers were encouraging. Stanford's 2026 AI Index reports that 88% of surveyed organizations now use AI somewhere in the business. Budgets are growing. Vendor ecosystems are maturing.
The problem is that adoption and production are not the same thing, and April 2026 produced five signals that made the distance between them impossible to ignore.
Anthropic shifted Claude Enterprise off flat pricing because agent workloads broke the SaaS model. A new dbt Labs report quantified how much faster teams are generating AI output than they are governing the pipelines feeding it. OpenAI's GPT-5.5 launched simultaneously on Snowflake Cortex and Databricks, signaling that foundation models are commoditizing faster than enterprises can evaluate them. Stanford's numbers show that only 5-10% of organizations have scaled AI across any business function. And new benchmarks from Fivetran and dbt Labs reveal that more than half of enterprise engineering capacity is consumed by maintaining what already exists, before any new AI work begins.
Every one of these signals traces back to the same underlying question. AI is arriving faster than the infrastructure, economics, and operational discipline that were supposed to support it. Here is what each signal means and what enterprise data teams should do about it.
# 1. AI Pricing Is Breaking the SaaS Model
In mid-April, trade press confirmed what some enterprise Claude customers had been noticing for weeks. Anthropic had shifted Claude Enterprise off flat-rate per-user pricing and onto a usage-based billing model. Customers now pay a base seat fee plus actual compute consumption drawn from a shared organizational pool. Legacy contracts are transitioning at renewal.
The reason is agents. And a new telemetry report from Datadog shows exactly how badly flat-fee pricing has broken underneath the new workload patterns.
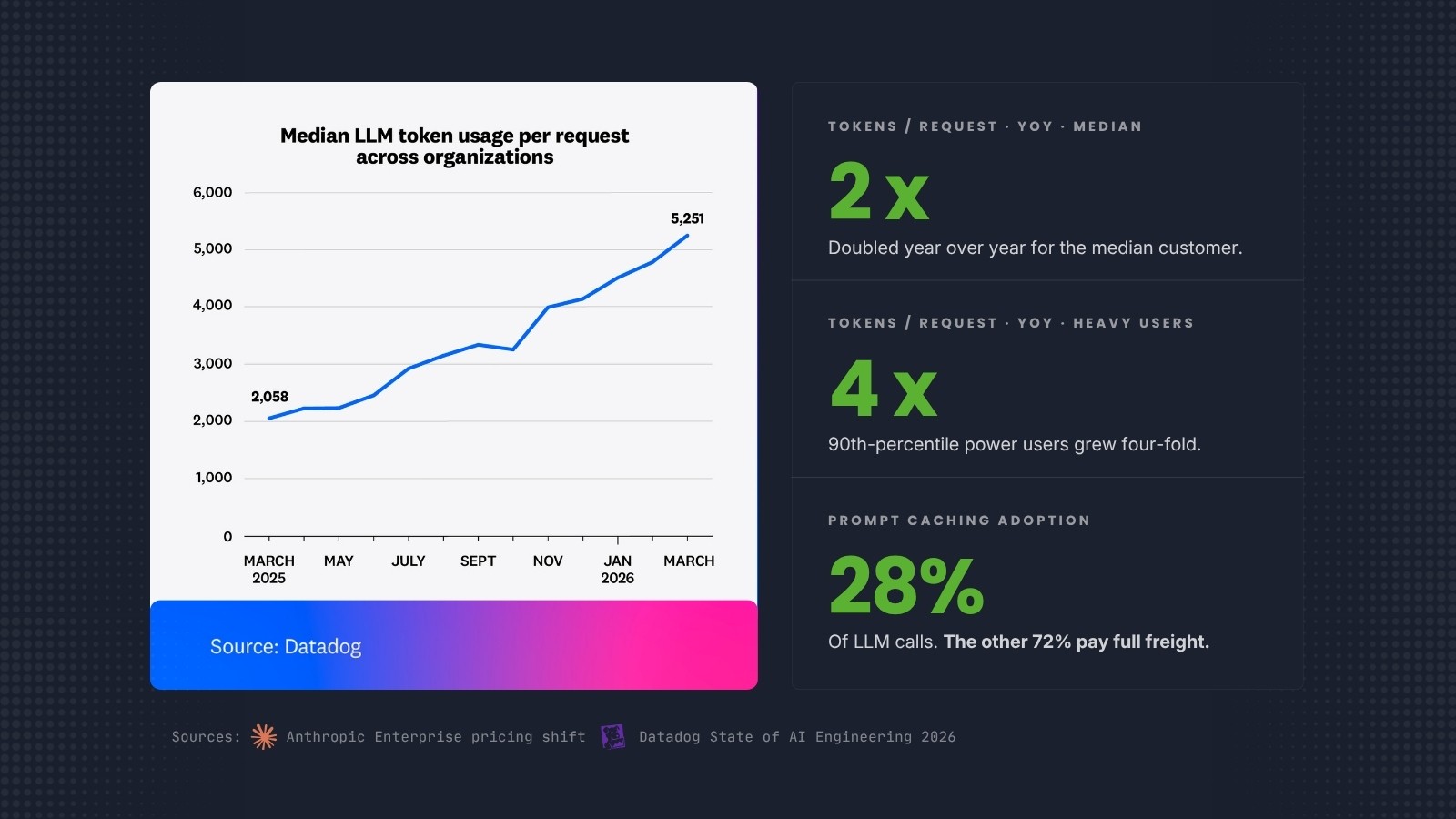
AI agents do not behave like human seats. A seat-based SaaS pricing model assumes a user logs in during business hours, runs some queries, and logs off. Agents run continuously. They query, process, iterate, and call other agents. They generate inference load 24 hours a day. Anthropic's own data shows the pattern: weekly active users of Claude Code doubled between January and February 2026. The compute demand that used to arrive in business-hour spikes now runs around the clock.
Datadog's State of AI Engineering 2026 report, built from telemetry across more than 1,000 enterprise customers, quantifies the consumption curve directly. Average tokens per LLM request more than doubled year over year for the median customer. For 90th-percentile power users, tokens per request quadrupled. System prompts alone consumed 69% of all input tokens in customer traces. And only 28% of LLM call spans showed any cached-read tokens, meaning the single largest cost optimization available to enterprises, prompt caching, is sitting unused in nearly three out of every four calls.
Flat-fee pricing cannot absorb that. Trade press reporting suggests Anthropic's shift could triple costs for some heavy enterprise customers.
What this means for enterprise data and finance teams is that AI is becoming a FinOps problem, not a procurement problem. The predictable SaaS line item in last year's budget is turning into a compute consumption line that scales with use. Finance teams that were ready to approve a seat count are now being asked to approve a throughput forecast. The organizations that treat AI spend like cloud spend, with usage monitoring, cost allocation, and consumption governance, will manage the transition without surprise. The organizations that treat it like SaaS will learn the new economics from an invoice. Building that operational discipline in-house is hard; running it as an ongoing engagement is what managed services is built for.
The broader lesson is that when the frontier lab selling the agents publicly changes how it charges for them, and the observability vendor watching actual production traffic confirms why, it is telling the market how the underlying economics actually work. Listen to what Anthropic is saying about inference cost and capacity. Listen to what Datadog is showing about token growth and untouched optimization levers. Build the budget model accordingly.

2. The Most Expensive Demo Your CFO Will Ever Watch
A pattern we have been hearing in enterprise conversations throughout the month: leadership wants an AI win, someone wires an LLM directly into the data lake or warehouse, the output looks impressive in the demo, and then the monthly bill arrives.
The dbt Labs 2026 State of Analytics Engineering Report quantified what is happening underneath. Among the 363 data practitioners and leaders surveyed, 72% said they are prioritizing AI-assisted coding. Only 24% said they are prioritizing AI-assisted pipeline management. That is a three-to-one gap between teams racing to generate AI output and teams investing in the pipelines, data quality, and governance that feed it.
The subtitle of the report says it plainly: "AI is outpacing trust and governance." 71% of respondents are concerned about hallucinated or incorrect data reaching stakeholders. 53% cite poor data quality as their most frequent challenge. Trust in data jumped from a 66% priority in 2025 to 83% in 2026, a 17-point increase in a single year.
The pattern is consistent across client engagements. Pointing an LLM at an ungoverned lakehouse is not an AI strategy. It is a compute expense with a probability distribution of wrong answers attached. The demo works because the demo uses clean inputs. Production breaks because production data includes the three-year-old schema drift, the undocumented business logic buried in a stored procedure, and the table nobody realized was being partially refreshed.
The AI layer amplifies whatever the data layer gives it. Clean, governed, documented data pipelines produce reliable AI outputs at predictable cost. Ungoverned data produces expensive mistakes that the compute bill makes visible before the business logic problems do.
The organizations getting AI right in 2026 are doing the governance work first, then layering AI on top. The sequence matters. It is not an accident that Stanford's data shows companies with mature AI governance deploy 12x more AI projects to production than companies without it. The governance is not a tax. It is the load-bearing wall.
#3. Foundation Models Are Commoditizing Faster Than Enterprises Can Evaluate Them
On April 28, OpenAI released GPT-5.5. The same day, the model was generally available on both Snowflake Cortex AI and Databricks. Two of the three major enterprise data platforms shipped a new frontier model on day one. Microsoft Fabric is expected to follow shortly via Azure OpenAI Service.
A year ago, model availability was a meaningful platform differentiator. An enterprise picking between Snowflake and Databricks could legitimately consider which lab's models would arrive first on which platform. That window has closed. The frontier labs have learned that simultaneous cross-platform availability is the table stakes their enterprise customers expect, and the platform vendors have built the integrations to make it possible.
The consequence runs deeper than vendor selection. If foundation models are commodity-shipped across all major data platforms simultaneously, the model layer is no longer the differentiator. The data layer is. The governance layer is. The operational discipline that turns a model into a reliable production system is. These are not platform features; they are organizational capabilities.
The platform decision question has changed shape. The old form: "Which platform will give us the best AI capabilities?" The new form: "Which platform will let us govern, monitor, and operate AI at production scale most reliably?" The first question is being answered by the model vendors. The second question is what the platform decision is actually about now.
Smart Data delivery teams have watched this shift accelerate over the last six months. Enterprises that used to ask "which AI platform should we choose" are now asking "how do we make any of them produce trustworthy outputs in production." The platform becomes a substrate. The foundation work becomes the strategy.
The organizations that recognize this are reallocating AI investment away from model selection and into the data, governance, and operational layers. The organizations still treating the platform decision as the AI strategy are spending budget on a question the market has already answered. The cross-platform availability of GPT-5.5 is the clearest signal yet that the answer has shifted, and it shifted faster than most procurement cycles can keep up with.
#4. Adoption Is Not Scale
Stanford HAI's 2026 AI Index Report, published April 13, is the most comprehensive independent survey of the AI landscape each year. The 2026 edition makes one thing obvious.
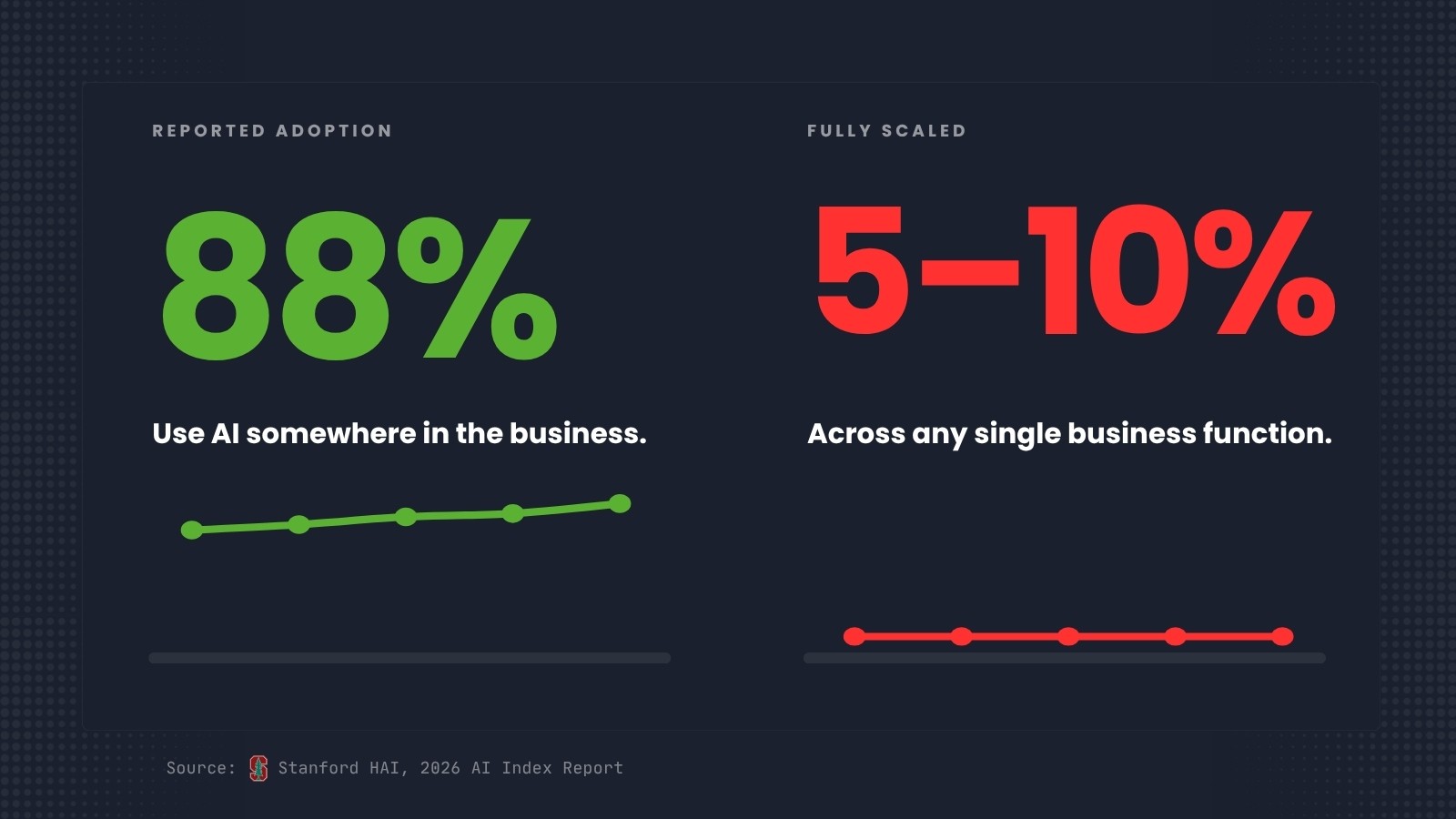
88% of surveyed organizations now use AI in some capacity. This is the adoption number that gets quoted in every board deck. The problem is the next number. Only 5-10% of organizations have fully scaled AI across any business function. Agent deployment is in single digits across nearly every business function tracked.
Adoption is not scale. A marketing team running ChatGPT for copy drafts counts in the 88%. A finance team using an AI assistant for spreadsheet formulas counts in the 88%. A governed agent embedded in a revenue workflow that is driving measurable business outcomes is in the 5-10%, and for most organizations, it is not there at all.
The gap between 88% and 10% is the reason [so many AI initiatives look like failures](/blog/why-enterprise-ai-investments-fail). Organizations that budgeted for production AI and ended up with a collection of productivity tools are not getting the returns the business case promised, because the business case assumed production deployment and the actual deployment is pilot mode.
The organizations that have bridged the gap share a pattern. They invested in the data foundation, the governance structure, and the architecture before adding the AI layer. Deloitte's 2026 State of AI in the Enterprise report documents the same pattern from a different angle: only 25% of organizations have moved 40% or more of their AI experiments into production. The 75% stuck in pilot mode are the 75% that skipped the foundation work.
For enterprise leaders, the practical question this quarter is not "are we using AI." It is "where is the production deployment, and where is the ROI." Those two questions have the same answer, and it is not a model choice. It is an architecture decision that was made, or not made, 18 months ago. The organizations that made it are scaling. The organizations that did not are rebuilding backwards.

#5. The Firefighting Tax
The honest math on enterprise data team capacity is uncomfortable, and April 2026 produced two independent benchmarks that quantified it precisely.
Fivetran's 2026 Enterprise Data Infrastructure Benchmark Report found that 53% of engineering time across enterprise data teams goes to pipeline maintenance. The dbt Labs and Harris Poll Analyst Revolution report, separately, found that 78% of analysts' time is consumed by busywork: data preparation, validation, navigating fragmented tool landscapes. For a 1,000-analyst enterprise, dbt Labs estimates the hidden productivity tax at $21.6 million annually. Pipeline downtime, when it hits, costs an average of $49,600 per hour according to the Fivetran benchmark.
More than half of your engineering capacity is spent keeping existing systems running. Less than half remains for the AI work, the analytics improvements, the platform migrations, and the modernization that the business is asking for. Every new AI project competes with the maintenance backlog for the same engineering hours. When leadership asks why the AI initiative is taking 18 months instead of six, the answer is in this number. The team is not slow. The team is fighting fires.
The firefighting problem is structural, not individual. It persists because data pipelines were built incrementally without quality frameworks, because governance exists in documentation but not in automated checks, and because each new tool adds complexity without reducing maintenance load. The pattern compounds. A team firefighting last year is firefighting more this year, because the maintenance debt grew faster than the tooling improved.
The teams that break the firefighting cycle are not the ones that hire more engineers. Adding capacity to a maintenance-heavy environment increases maintenance, not output. The teams that break the cycle invest in data quality frameworks and governance structures that prevent issues from reaching production in the first place. Automated quality checks at the staging layer. Lineage tracking that surfaces upstream changes before they break downstream models. Observability that catches anomalies in hours instead of after a week of stakeholder questions.
Governance does not slow teams down. It prevents the fires that slow teams down.
The Databricks finding from earlier in this post bears repeating in this context: companies investing in AI governance see 12x more projects reach production. That is not a statement about model deployment efficiency. It is a statement about engineering capacity. Governance frees the time that builds the next thing.
For organizations whose engineering teams are spending more time maintaining than building, the foundation question is not "should we add governance." It is "how much of our team's time can we recover by adding governance, and what would that recovered time make possible." Recovering even 10% of the 53% currently consumed by maintenance is a multi-million-dollar capacity gain, before any new hire, before any new platform purchase, before any new AI initiative.
Not sure if your data is ready for AI?
Start with our AI Enablement Guide to assess where your organization stands before committing to an implementation.
What All Five Signals Share
Pricing. Governance. Platforms. Scale. Operations.
The signals look like five different stories about AI. They are one story about infrastructure.
In every case, AI arrived faster than the supporting system was ready to handle it. SaaS pricing cannot absorb agent workloads. Data pipelines cannot absorb AI output volumes without governance. Platform features cannot differentiate when frontier models ship cross-platform on day one. Pilot architectures cannot absorb production deployment. And engineering capacity cannot absorb new AI work when more than half of it is already consumed by firefighting.
The enterprises that will win in 2026 are not the ones with the best models. Stanford's data makes this clear. The performance gap between leading models is shrinking toward zero. What differentiates outcomes is whether the organization around the model is built to absorb it.
Pricing models that track actual consumption. Data governance that keeps pace with AI output. Platform decisions that prioritize governance and operations over feature parity. Architectures that move pilots to production. And operational discipline that frees engineering time from firefighting so teams can build the next thing.
None of this is new work. It is foundational work that the last decade of digital transformation was supposed to produce. What AI has done is make the gaps visible and expensive at the same time.
The question your board will ask in the next quarter is some version of "what is our AI strategy." The honest answer is that the strategy is the foundation work. The model choice is downstream of whether the data, architecture, governance, economics, and operations are ready to absorb production AI.
Smart Data helps enterprises assess, build, and govern those foundations. Our Data Quality and Governance workshop produces the governance framework that lets AI output scale without losing trust. Our AI Enablement workshop produces the architecture and production deployment plan. Our Data Platform Strategy workshop evaluates the cost structure and platform choices that determine whether AI is a predictable line item or a runaway consumption problem. Our Managed Services engagements provide the dedicated teams that keep all three running reliably in production.
If any of the five signals in this post sound familiar in your organization, the foundation is the conversation to have. Start Here.
*Sources: [The Register, "Anthropic ejects bundled tokens from enterprise seat deal" (April 16, 2026)](https://www.theregister.com/2026/04/16/anthropic_ejects_bundled_tokens_enterprise/); [PYMNTS, "Anthropic Switches to Usage-Based Billing for Enterprise Customers" (April 2026)](https://www.pymnts.com/artificial-intelligence-2/2026/anthropic-switches-to-usage-based-billing-for-enterprise-customers/); [Datadog, "State of AI Engineering 2026"](https://www.datadoghq.com/state-of-ai-engineering/); [dbt Labs, "2026 State of Analytics Engineering Report"](https://www.getdbt.com/resources/state-of-analytics-engineering-2026); [Snowflake Blog, "OpenAI GPT-5.5 on Snowflake Cortex AI" (April 28, 2026)](https://www.snowflake.com/en/blog/openai-gpt-55-snowflake-cortex-ai/); [Databricks Blog, "OpenAI GPT-5.5 + Codex on Databricks" (April 28, 2026)](https://www.databricks.com/blog/openai-gpt-55-codex); [Stanford HAI, "2026 AI Index Report" (April 13, 2026)](https://hai.stanford.edu/ai-index/2026-ai-index-report); [Fivetran, "Enterprise Data Infrastructure Benchmark Report 2026"](https://www.fivetran.com/blog/the-enterprise-data-infrastructure-benchmark-report-2026); dbt Labs and Harris Poll, "The Analyst Revolution"; Deloitte, "2026 State of AI in the Enterprise."*

